NNCでディープラーニング
実際に体験
まずデータを収集するために、「ヴァイオリン」に似ている「コントラバス」、少し似ている「ギター」、それぞれの画像を検索してファイルにまとめました。
 それらのデータとExcelを使用して「ヴァイオリン」を1、「コントラバス」「ギター」を0としてデータセット(学習用と評価用)を作成しました。
それらのデータとExcelを使用して「ヴァイオリン」を1、「コントラバス」「ギター」を0としてデータセット(学習用と評価用)を作成しました。
 この2つのデータセットをNNCにアップロードし、
この2つのデータセットをNNCにアップロードし、

プロジェクトを編集し、

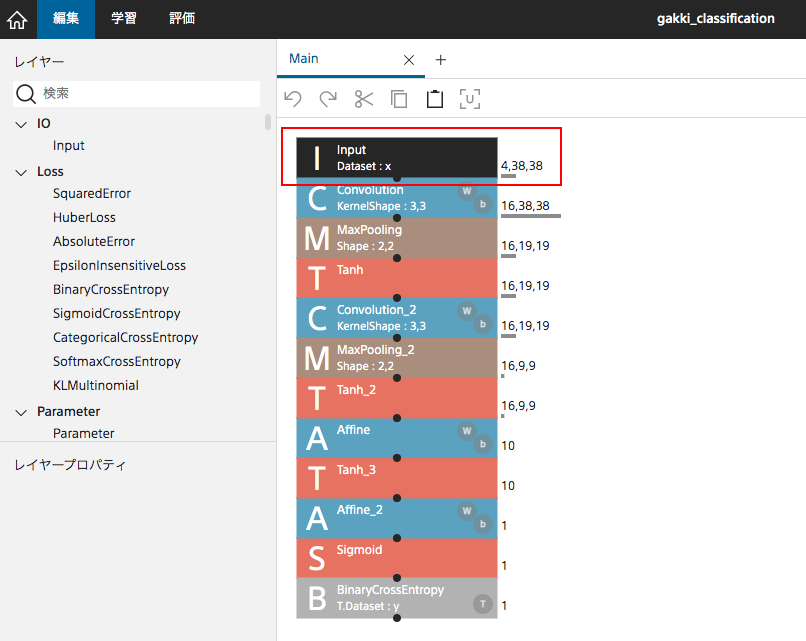 学習・評価を3回行いました。
学習・評価を3回行いました。

 学習結果には
学習結果には
まとめ・考察
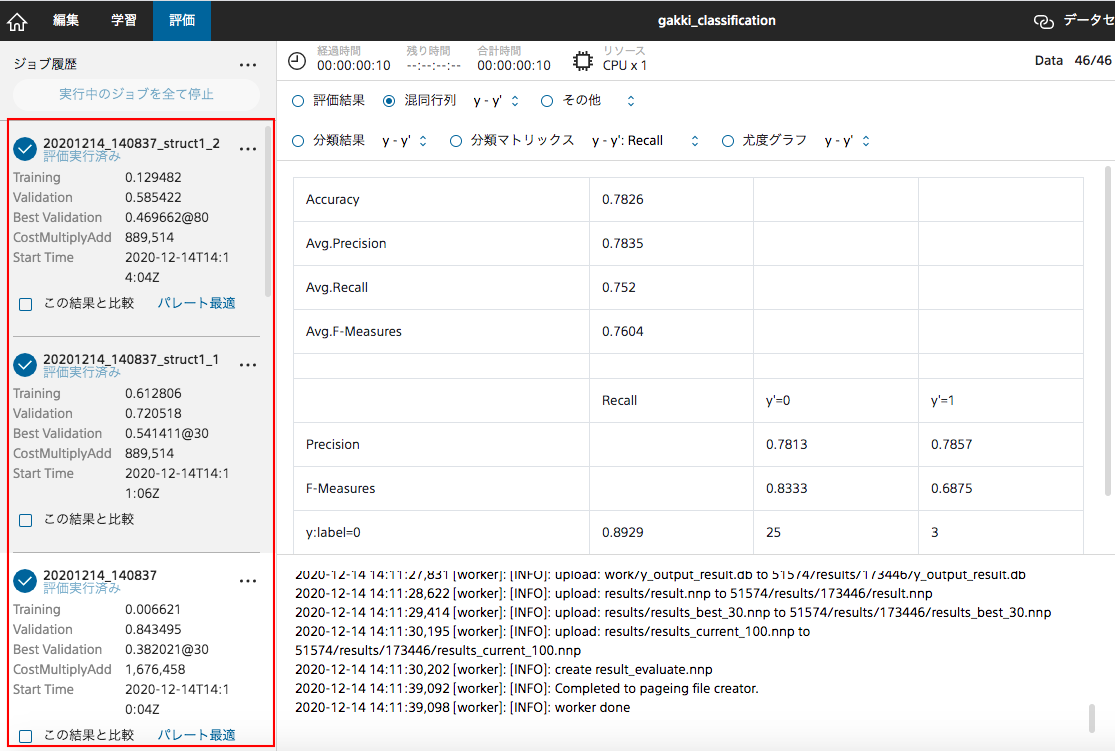
 図1 学習精度・再現度・適合度
上の図1は3回分の学習精度、再現率、適合率です。
再現率:正解からみて正解と出力の分類結果が一致しているデータの割合
適合率:出力から見て正解と出力の分類結果が一致しているデータの割合
学習精度の平均は71.01%となりました。2回目の精度は最も低く、ギター、コントラバスの画像に対しての適合率と一致したことから、2回目ではギター、コントラバスの画像の学習のみが行えたと考えます。
『ソニー開発のNeural Network Console入門』に載っていた、4と9の手書き文字を分類させる学習の精度は95%、犬を識別させる学習の精度は100%だったことから、機械にとってもヴァイオリン、ギター、コントラバスのような似た楽器の分類をするのは難しいのだと分かりました。
図1 学習精度・再現度・適合度
上の図1は3回分の学習精度、再現率、適合率です。
再現率:正解からみて正解と出力の分類結果が一致しているデータの割合
適合率:出力から見て正解と出力の分類結果が一致しているデータの割合
学習精度の平均は71.01%となりました。2回目の精度は最も低く、ギター、コントラバスの画像に対しての適合率と一致したことから、2回目ではギター、コントラバスの画像の学習のみが行えたと考えます。
『ソニー開発のNeural Network Console入門』に載っていた、4と9の手書き文字を分類させる学習の精度は95%、犬を識別させる学習の精度は100%だったことから、機械にとってもヴァイオリン、ギター、コントラバスのような似た楽器の分類をするのは難しいのだと分かりました。

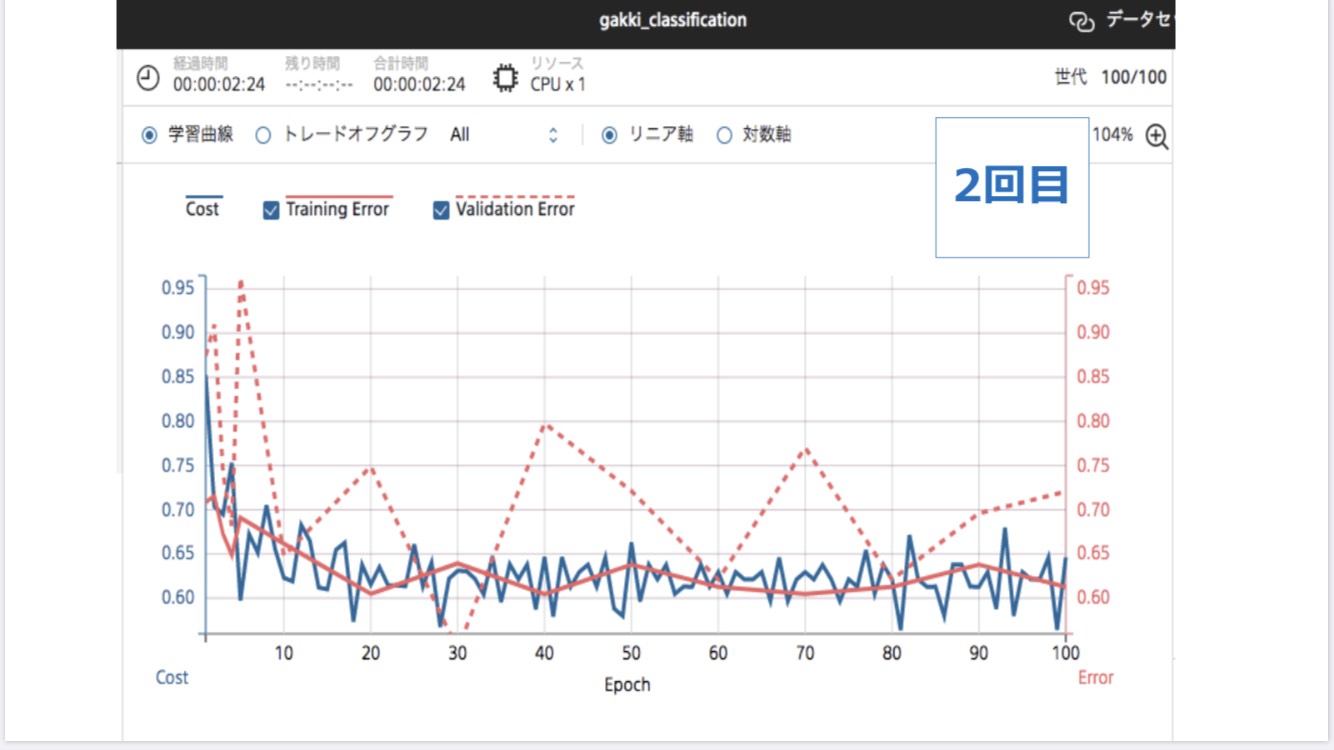
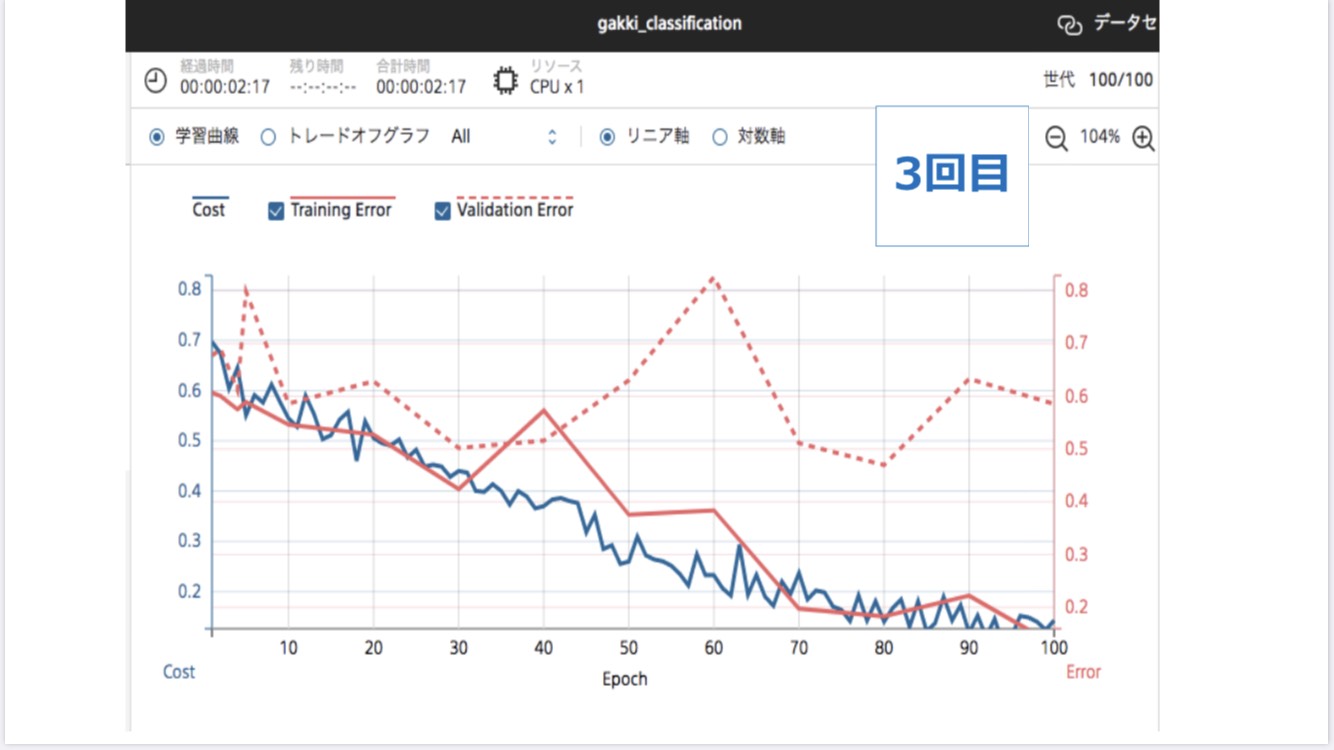 図2 1~3回目の学習曲線
上の図2は3回の学習の学習曲線です。横軸は学習回数、縦軸は学習と評価データの誤差関数です。Training Error(ピンクの直線)は学習誤差、Validation Error(ピンクの実線)は評価誤差を示します。1回目と3回目では、100回の学習を終えて学習誤差がほぼ0になりましたが、2回目では0.60あたりにとどまりました。また、1回目では学習誤差が緩やかに減少しましたが、2回目と3回目では増減を繰り返しました。評価誤差を見ると、どの回も増減を繰り返し、山と谷の数は2回目、3回目、1回目の順に多いです。
このことから、3回目の学習結果は1回目と2回目の学習結果の間をとっているように見えるなと思いました。よって機械学習で学習の質を整えるためには、同じ学習の回数を増やす必要があると考えます。
図2 1~3回目の学習曲線
上の図2は3回の学習の学習曲線です。横軸は学習回数、縦軸は学習と評価データの誤差関数です。Training Error(ピンクの直線)は学習誤差、Validation Error(ピンクの実線)は評価誤差を示します。1回目と3回目では、100回の学習を終えて学習誤差がほぼ0になりましたが、2回目では0.60あたりにとどまりました。また、1回目では学習誤差が緩やかに減少しましたが、2回目と3回目では増減を繰り返しました。評価誤差を見ると、どの回も増減を繰り返し、山と谷の数は2回目、3回目、1回目の順に多いです。
このことから、3回目の学習結果は1回目と2回目の学習結果の間をとっているように見えるなと思いました。よって機械学習で学習の質を整えるためには、同じ学習の回数を増やす必要があると考えます。
感想
機械も人と同じで何回も練習(学習)を繰り返すことが大事なのかなと思いました。より精度の高い学習にするためには、誤差を小さくする方法の模索や入力データ数を増やすと行った改善ができると思いました。