学習
ここでは、どのような手順でこのテーマを進めたかを紹介いたします。
使用したモデル
使用モデルは、独自で作成した日本語軽量化GPTです。
作成するにあたり、rinna株式会社が開発した
japanese-gpt-neox-smallと呼ばれるモデルを参考にしてパラメータを設定しました。
また、学習の際には、NVIDIA社の"V100"とよばれるGPUを使用しました。
(GPUを使用した理由については技術調査のおまけを参照してください。)
1:日本語wikipedia全文のコーパスでの事前学習
日本語wikipedia全文のデータを入手しコーパスを作成し事前学習を行いました。
コーパスを作成する際、あらかじめテキストデータをトークン化して保存することで学習時の前処理時間を削減しました。
トークン化とは、テキストを個々のトークンと呼ばれる小さな単位に分割することです。
その後事前学習を4epoch分行いました。(=データのセットを4周してパラメータを調整しました)
作成されたモデルのloss値は以下の図1のようになりました。loss値とは正解値からどれくらいズレているかという、ズレの大きさのことです。
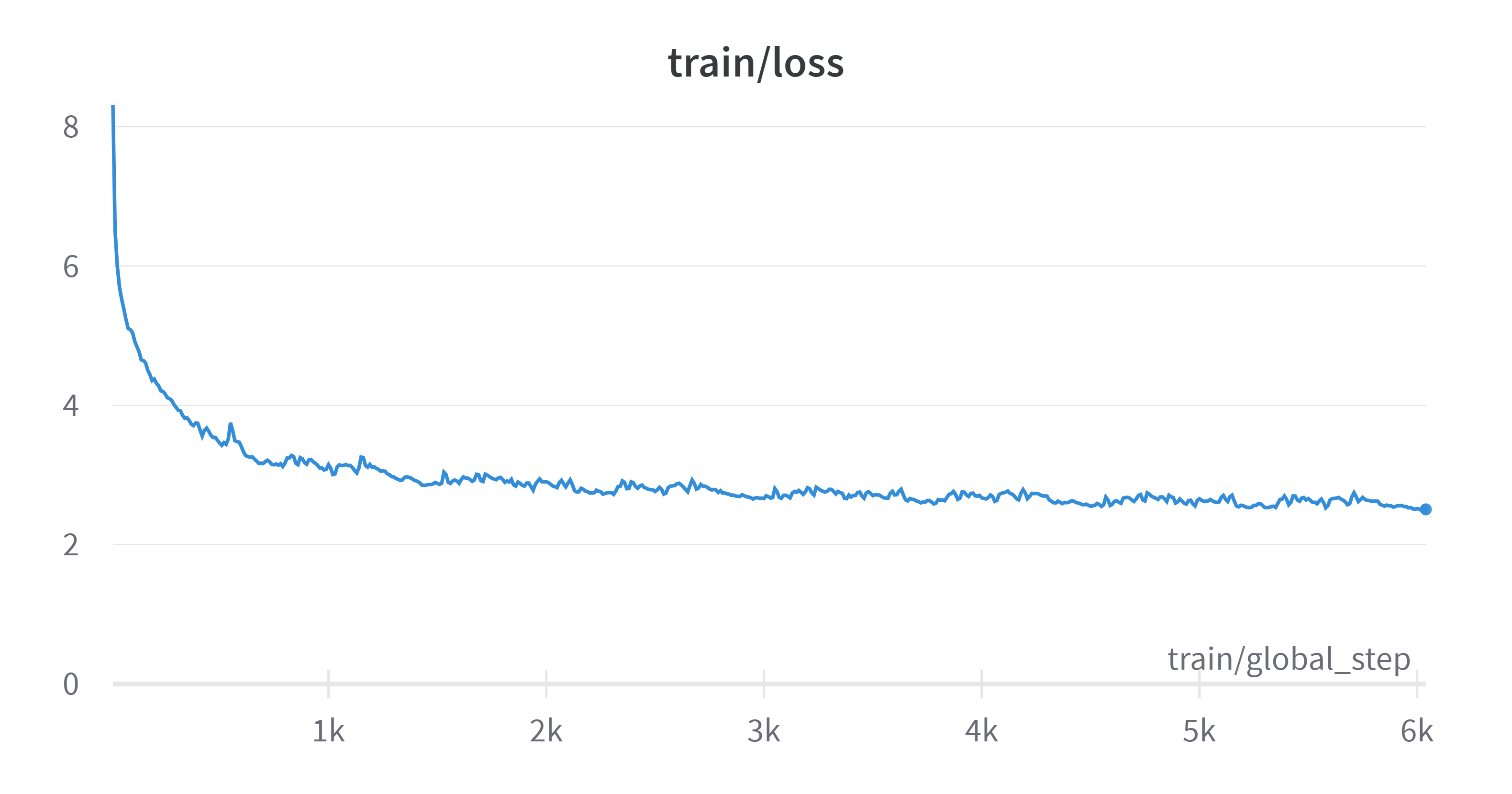 図1 loss値
図1 loss値
2:ファインチューニング用のコーパス準備
GitHub上で青空文庫が公開している小説のテキストデータセット(著作権切れの年代)をダウンロードし、小説に関する情報やルビの付け方など文章と関係性のない内容の物を消すいわゆるクリーニングと呼ばれる作業を行いました。
その後ある文章を入力するとその続きの文章を推論してもらうために文書の冒頭部分と続きの部分が対になったコーパスを準備しました。
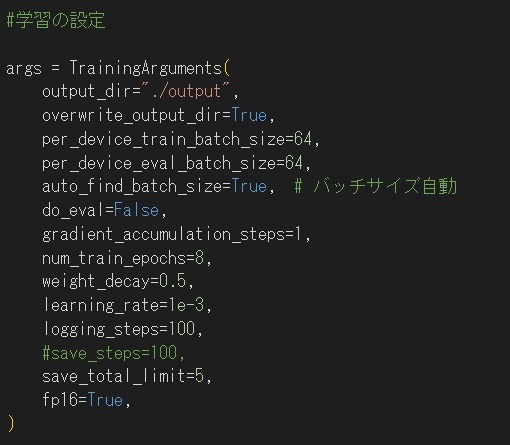
3:ファインチューニング
手順1で事前学習させたモデルに対して、トークン化を行った後に以下の変数を用いてFine-Tuningを行いました。